
Die Überwachung von Deadlocks und anderen Leistungsproblemen ist entscheidend für die Aufrechterhaltung der Gesundheit und Effizienz eines Data Warehouses. Hier sind einige SQL-Abfragen, die Ihnen helfen können, Deadlocks und verwandte Probleme auf einem Microsoft SQL Server zu überwachen:
Deadlock-Graphen aus den System Health Extended Events abrufen:
WITH xDeadlock AS
(
SELECT CAST(target_data AS XML) AS TargetData
FROM sys.dm_xe_session_targets st
JOIN sys.dm_xe_sessions s ON s.address = st.event_session_address
WHERE name = 'system_health' AND target_name = 'ring_buffer'
)
SELECT TargetData.query('//event/data/value/deadlock') AS DeadlockGraph
FROM xDeadlock;
-----Beachten Sie, dass dies Ihnen XML-Daten gibt, die die Deadlock-Graphen darstellen.Informationen zu blockierten Prozessen abrufen:
SELECT blocking_session_id AS BlockingSessionID, session_id AS BlockedSessionID,
wait_time, wait_type, resource_description
FROM sys.dm_os_waiting_tasks
WHERE blocking_session_id IS NOT NULL;Informationen über lange laufende Abfragen:
SELECT session_id, start_time, status, command,
total_elapsed_time/1000 AS TotalElapsedTimeSeconds,
TEXT AS QueryText
FROM sys.dm_exec_requests
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
WHERE total_elapsed_time > 60000; -- z.B. Abfragen, die länger als 60 Sekunden laufenErfassung von Leistungsstatistiken für Abfragen:
SELECT creation_time, last_execution_time, total_physical_reads,
total_logical_writes, total_logical_reads, execution_count,
total_worker_time, total_elapsed_time, total_clr_time,
TEXT AS QueryText
FROM sys.dm_exec_query_stats
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
ORDER BY total_logical_reads DESC; -- Sortiert nach den meisten Lesevorgängen als BeispielInformationen über die CPU-Auslastung von SQL-Abfragen:
SELECT TOP 10 session_id, cpu_time, status, command,
TEXT AS QueryText
FROM sys.dm_exec_requests
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
ORDER BY cpu_time DESC;Ermittlung der Speicherauslastung von Objekten im Pufferpool:
SELECT OBJECT_NAME(p.object_id) AS ObjectName,
COUNT(*) * 8/1024 AS MemoryUsageMB
FROM sys.dm_os_buffer_descriptors bd
JOIN sys.allocation_units a ON bd.allocation_unit_id = a.allocation_unit_id
JOIN sys.partitions p ON a.container_id = p.hobt_id
WHERE bd.database_id = DB_ID()
GROUP BY p.object_id
ORDER BY MemoryUsageMB DESC;Aktuell aktive Benutzersitzungen und deren Aktivitäten anzeigen:
SELECT session_id, login_time, host_name, program_name, client_interface_name,
status, cpu_time, memory_usage, total_scheduled_time, total_elapsed_time
FROM sys.dm_exec_sessions
WHERE is_user_process = 1;Top N Abfragen mit den meisten Lesevorgängen:
SELECT TOP 10 SUBSTRING(qt.TEXT, (qs.statement_start_offset/2) + 1,
((CASE qs.statement_end_offset WHEN -1 THEN DATALENGTH(qt.TEXT)
ELSE qs.statement_end_offset END - qs.statement_start_offset)/2) + 1) AS QueryText,
qs.total_logical_reads
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
ORDER BY qs.total_logical_reads DESC;Datenbankgrößen und -nutzungen anzeigen:
SELECT name AS DatabaseName, size/128.0 AS SizeInMB,
CASE WHEN is_read_only = 1 THEN 'ReadOnly' ELSE 'ReadWrite' END AS AccessMode
FROM sys.master_files
WHERE type = 0;Ermitteln Sie die durchschnittliche Wartezeit für verschiedene Wartetypen:
SELECT wait_type, SUM(wait_duration_ms) AS TotalWaitTimeMs,
COUNT(*) AS WaitCount,
SUM(wait_duration_ms) / COUNT(*) AS AvgWaitTimeMs
FROM sys.dm_os_wait_stats
WHERE wait_type NOT IN ('CLR_SEMAPHORE', 'LAZYWRITER_SLEEP', 'RESOURCE_QUEUE',
'SLEEP_TASK', 'SLEEP_SYSTEMTASK', 'SQLTRACE_BUFFER_FLUSH', 'WAITFOR', 'LOGMGR_QUEUE',
'CHECKPOINT_QUEUE', 'REQUEST_FOR_DEADLOCK_SEARCH', 'XE_TIMER_EVENT', 'BROKER_TO_FLUSH',
'BROKER_TASK_STOP', 'CLR_MANUAL_EVENT', 'CLR_AUTO_EVENT', 'DISPATCHER_QUEUE_SEMAPHORE',
'FT_IFTS_SCHEDULER_IDLE_WAIT', 'XE_DISPATCHER_WAIT', 'XE_DISPATCHER_JOIN')
GROUP BY wait_type
ORDER BY AvgWaitTimeMs DESC;Überwachung der I/O-Leistung für Datenbankdateien:
SELECT DB_NAME(database_id) AS DatabaseName,
file_id, io_stall_read_ms, io_stall_write_ms,
num_of_reads, num_of_writes,
size_on_disk_bytes/1024.0/1024.0 AS SizeOnDiskMB
FROM sys.dm_io_virtual_file_stats(NULL, NULL);Ermitteln von Plan-Cache-Statistiken (um ineffiziente Abfragepläne zu identifizieren):
SELECT objtype AS ObjectType,
COUNT(*) AS TotalObjects,
SUM(size_in_bytes) / 1024.0 / 1024.0 AS TotalMB
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY TotalMB DESC;Verfolgen von TempDB-Nutzung:
SELECT SUM(user_object_reserved_page_count) * 8 AS UserObjectSizeKB,
SUM(internal_object_reserved_page_count) * 8 AS InternalObjectSizeKB,
SUM(version_store_reserved_page_count) * 8 AS VersionStoreSizeKB,
SUM(unallocated_extent_page_count) * 8 AS FreeSpaceKB
FROM sys.dm_db_file_space_usage;Überwachung des Puffer-Cache-Hits:
SELECT (CAST(COUNT(*) AS FLOAT) - SUM(CAST(page_life_expectancy AS FLOAT)))/COUNT(*) AS 'Buffer Cache Hit Ratio'
FROM sys.dm_os_performance_counters
WHERE object_name = 'SQLServer:Buffer Manager' AND counter_name = 'Page life expectancy';Ermittlung der Anzahl aktiver Benutzerprozesse:
SELECT COUNT(*) AS NumberOfActiveSPIDs
FROM sys.sysprocesses
WHERE status = 'runnable' OR status = 'running';Ermittlung der durchschnittlichen Ladezeit für Abfragen:
SELECT AVG(total_elapsed_time) AS AvgElapsedTime, SUBSTRING(TEXT, 1, 100) AS TextFragment
FROM sys.dm_exec_requests
CROSS APPLY sys.dm_exec_sql_text(sql_handle);Überwachung des SQL Server-Fehlerprotokolls auf kritische Fehler:
EXEC sp_readerrorlog 0, 1, 'error';Ermittlung der Prozesse, die den meisten Arbeitsspeicher verwenden:
SELECT session_id, text AS QueryText, memory_usage * 8 AS MemoryUsageKB
FROM sys.dm_exec_requests
JOIN sys.dm_exec_sessions ON sys.dm_exec_requests.session_id = sys.dm_exec_sessions.session_id
CROSS APPLY sys.dm_exec_sql_text(sql_handle)
ORDER BY memory_usage DESC;Ermittlung der teuersten Abfragen im Hinblick auf CPU-Nutzung:
SELECT TOP 10 SUBSTRING(qt.TEXT, (qs.statement_start_offset/2) + 1,
((CASE qs.statement_end_offset WHEN -1 THEN DATALENGTH(qt.TEXT)
ELSE qs.statement_end_offset END - qs.statement_start_offset)/2) + 1) AS QueryText,
qs.total_worker_time AS TotalCPUTime,
qs.execution_count AS ExecutionCount,
qs.total_worker_time/qs.execution_count AS AvgCPUTime
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
ORDER BY qs.total_worker_time DESC;Überprüfung der Netzwerkauslastung des SQL Servers:
SELECT instance_name AS Interface,
(cntr_value * 1.0 / 1024) AS BandwidthInMBps
FROM sys.dm_os_performance_counters
WHERE counter_name = 'Bytes Received/sec' OR counter_name = 'Bytes Sent/sec';Ermittlung von Tabellen mit fehlenden Indizes:
SELECT OBJECT_NAME(dm_mid.object_id) AS TableName,
dm_migs.avg_total_user_cost * dm_migs.avg_user_impact * (dm_migs.user_seeks + dm_migs.user_scans) AS Impact,
'CREATE INDEX missing_index_' + CONVERT(VARCHAR, dm_mid.index_handle) + ' ON ' + dm_mid.statement + ' (' + ISNULL(dm_mid.equality_columns, '') + CASE WHEN dm_mid.equality_columns IS NOT NULL AND dm_mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(dm_mid.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + dm_mid.included_columns + ')', '') AS CreateIndexStatement
FROM sys.dm_db_missing_index_groups dm_mig
JOIN sys.dm_db_missing_index_group_stats dm_migs ON dm_mig.index_group_handle = dm_migs.group_handle
JOIN sys.dm_db_missing_index_details dm_mid ON dm_mig.index_handle = dm_mid.index_handle
ORDER BY Impact DESC;Größte Tabellen in der Datenbank (nach Zeilenanzahl):
SELECT OBJECT_NAME(object_id) AS TableName, SUM(row_count) AS TotalRows
FROM sys.dm_db_partition_stats
WHERE index_id = 0 OR index_id = 1
GROUP BY object_id
ORDER BY TotalRows DESC;Ermittlung von Abfragen mit hohen Schreibvorgängen:
SELECT TOP 10 SUBSTRING(qt.TEXT, (qs.statement_start_offset/2) + 1,
((CASE qs.statement_end_offset WHEN -1 THEN DATALENGTH(qt.TEXT)
ELSE qs.statement_end_offset END - qs.statement_start_offset)/2) + 1) AS QueryText,
qs.total_logical_writes
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) qt
ORDER BY qs.total_logical_writes DESC;Ermittlung der gesamten Schreib- und Lese-I/O pro Datenbank:
SELECT DB_NAME(database_id) AS DatabaseName,
SUM(num_of_bytes_read + num_of_bytes_written) AS TotalIO
FROM sys.dm_io_virtual_file_stats(NULL, NULL)
GROUP BY database_id
ORDER BY TotalIO DESC;Ermittlung der Gesamtzeit, die Abfragen in der Warteschlange verbringen:
SELECT SUM(total_elapsed_time - total_worker_time) AS TotalWaitTime
FROM sys.dm_exec_requests;Ermittlung der Gesamtzeit, die Abfragen in der Warteschlange verbringen, unterteilt nach Wartetyp:
SELECT wait_type, SUM(wait_duration_ms) AS TotalWaitTime
FROM sys.dm_os_wait_stats
GROUP BY wait_type
ORDER BY TotalWaitTime DESC;Prüfen der Größe des Plan-Cache und der Anzahl der Cached-Pläne:
SELECT COUNT(*) AS CachedPlans, SUM(size_in_bytes) / 1024 / 1024 AS CacheSizeMB
FROM sys.dm_exec_cached_plans;Ermittlung der Top N Abfragen, die den Plan-Cache am meisten nutzen:
SELECT TOP 10 cp.size_in_bytes, DB_NAME(st.dbid) AS DatabaseName,
OBJECT_NAME(st.objectid) AS ObjectName, st.TEXT AS QueryText
FROM sys.dm_exec_cached_plans cp
CROSS APPLY sys.dm_exec_sql_text(cp.plan_handle) st
ORDER BY cp.size_in_bytes DESC;Prüfen der CPU-Auslastung von SQL Server im Vergleich zur Gesamtauslastung des Systems:
SELECT SQLProcessUtilization AS SQLServerCPU,
SystemIdle AS SystemIdleProcess,
100 - SystemIdle - SQLProcessUtilization AS OtherProcessesCPU
FROM sys.dm_os_ring_buffers
WHERE record_id = 1;Ermittlung der Anzahl von Deadlocks pro Tag aus dem System Health Extended Event:
WITH Deadlocks AS
(
SELECT
CAST(target_data AS XML) AS TargetData
FROM sys.dm_xe_session_targets st
JOIN sys.dm_xe_sessions s ON s.address = st.event_session_address
WHERE name = 'system_health' AND target_name = 'ring_buffer'
),
DeadlockDates AS
(
SELECT
CAST(TargetData.value('(/event/@timestamp)[1]', 'DATETIME') AS DATE) AS DeadlockDate,
TargetData
FROM Deadlocks
)
SELECT
COUNT(*) AS DeadlockCount,
DeadlockDate
FROM DeadlockDates
CROSS APPLY TargetData.nodes('//event[@name="xml_deadlock_report"]') AS XEventData(XEvent)
GROUP BY DeadlockDate;
Diese Abfragen können Ihnen helfen, Performance-Probleme, Deadlocks und andere Probleme in Ihrem Data Warehouse zu identifizieren und zu diagnostizieren. Es ist wichtig, regelmäßig Überwachungs- und Diagnoseabfragen durchzuführen, um sicherzustellen, dass Ihr DWH effizient und reibungslos läuft.
MS SQL Server mit vorgefertigten Berichten für die Performance Überwachung
Microsoft SQL Server bietet eine Vielzahl von vorgefertigten Berichten in SQL Server Management Studio (SSMS), die Ihnen dabei helfen können, die Performance und Gesundheit Ihrer Datenbanken zu überwachen und zu analysieren. Diese Berichte sind in SSMS integriert und bieten visuelle Einblicke in verschiedene Aspekte des Servers und der Datenbanken.
Hier sind einige der wichtigsten vorgefertigten Performance-Berichte, die SQL Server bietet:
- Server Dashboard: Zeigt eine Übersicht über die Server-Aktivität, einschließlich der Anzahl der Benutzer mit aktiven Verbindungen, der Anzahl der blockierten Prozesse und des Durchsatzes.
- Performance – Top-Abfragen nach durchschnittlicher CPU-Zeit: Zeigt die Abfragen, die im Durchschnitt am meisten CPU-Zeit verbrauchen.
- Performance – Top-Abfragen nach gesamter I/O: Identifiziert Abfragen, die den meisten I/O-Verkehr verursachen.
- Performance – Top-Abfragen nach gesamter CPU-Zeit: Listet Abfragen auf, die die meiste CPU-Zeit über alle Ausführungen hinweg verbrauchen.
- Indexnutzungsstatistiken: Zeigt, welche Indizes häufig verwendet werden und welche möglicherweise überflüssig sind.
- Indexphysikalische Statistiken: Zeigt Informationen über die physische Struktur und Gesundheit von Indizes.
- Datenbankgrößen: Bietet einen Überblick über die Größe von Datenbanken und ihren Wachstumstrends.
- Disknutzungsstatistiken: Zeigt den Speicherplatzverbrauch der Datenbank und gibt Aufschluss darüber, wie der Speicherplatz verwendet wird.
- Wartestatistiken: Gibt Aufschluss darüber, wo die meiste Wartezeit im System auftritt, was bei der Diagnose von Performance-Engpässen hilfreich sein kann.
- Speichernutzungsstatistiken: Zeigt, wie der SQL Server Arbeitsspeicher verwendet, einschließlich Pufferpool- und Verfahrenscache-Nutzung.
Um auf diese Berichte zuzugreifen:
- Öffnen Sie SQL Server Management Studio.
- Verbinden Sie sich mit Ihrer Datenbankinstanz.
- Klicken Sie im Objekt-Explorer mit der rechten Maustaste auf den Servernamen (für Serverberichte) oder den Datenbanknamen (für Datenbankberichte).
- Wählen Sie „Berichte“ > „Standardberichte“, und wählen Sie dann den gewünschten Bericht aus der Liste aus.
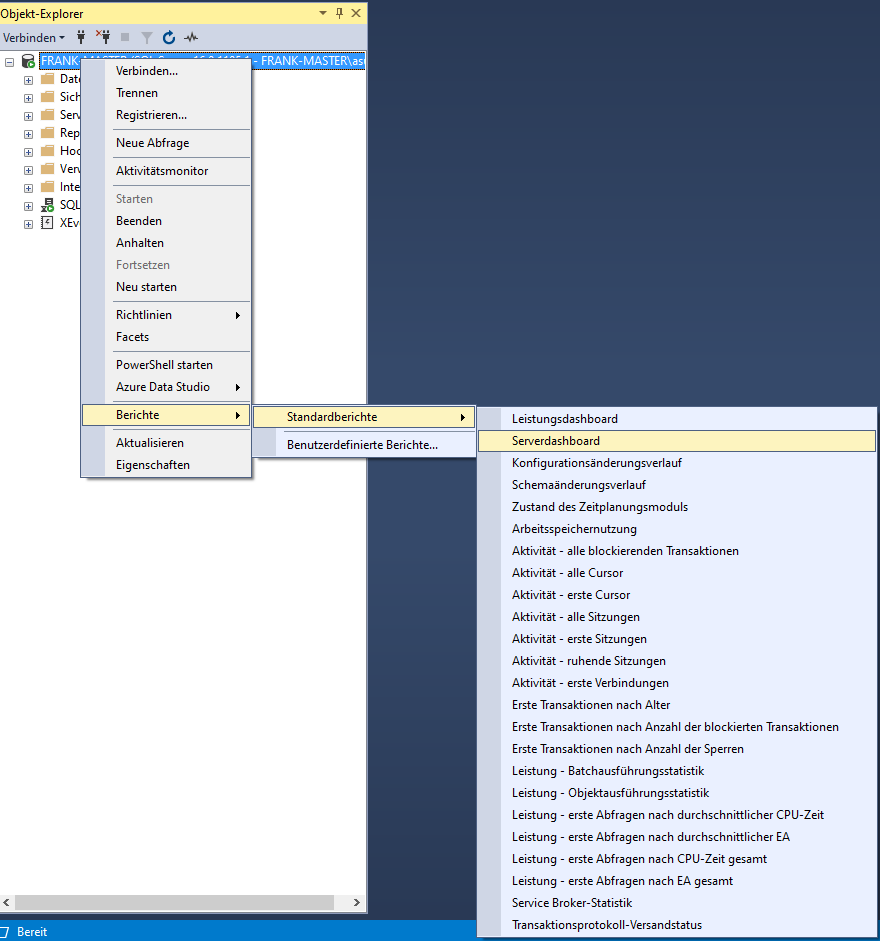
Beachten Sie, dass die Verfügbarkeit bestimmter Berichte von der Version und Edition von SQL Server abhängen kann. Es ist auch eine gute Idee, diese Berichte während Zeiten mit geringer Last auszuführen, da sie selbst Ressourcen verbrauchen können.
Benutzerdefinierte Berichte erstellen
In SQL Server Management Studio (SSMS) können Sie benutzerdefinierte Berichte erstellen und verwenden. Mit benutzerdefinierten Berichten können Sie spezifische Informationen in einer formatierten und leicht lesbaren Weise präsentieren, die nicht unbedingt durch die vorgefertigten Berichte abgedeckt wird.
Hier ist, was Sie mit benutzerdefinierten Berichten in SSMS tun können:
- Berichte erstellen: Sie können Ihre eigenen Berichte mit dem Microsoft Report Definition Language (RDL) Format erstellen. Dazu verwenden die meisten Entwickler den Microsoft Report Builder oder Visual Studio mit dem SQL Server Data Tools (SSDT) Plugin. Mit diesen Tools können Sie Datenquellen definieren, Abfragen erstellen und das Aussehen des Berichts gestalten.
- Berichte importieren: Wenn Sie einen benutzerdefinierten RDL-Bericht erhalten oder erstellt haben, können Sie ihn in SSMS importieren:
- Klicken Sie mit der rechten Maustaste auf den Server oder die Datenbank in SSMS.
- Wählen Sie „Berichte“ > „Benutzerdefinierte Berichte…“.
- Wählen Sie die RDL-Datei aus, die Sie hinzufügen möchten.
- Berichte ausführen: Nach dem Importieren eines benutzerdefinierten Berichts können Sie ihn genauso ausführen wie die vorgefertigten Berichte. Dies gibt Ihnen die Flexibilität, spezifische Daten in einem Format Ihrer Wahl zu präsentieren.
- Berichte teilen: Da benutzerdefinierte Berichte in RDL-Dateien gespeichert sind, können sie leicht zwischen verschiedenen SQL Server-Instanzen oder sogar mit anderen Entwicklern und Datenbankadministratoren geteilt werden.
- Parameter verwenden: In Ihren benutzerdefinierten Berichten können Sie Parameter verwenden, um interaktive Berichte zu erstellen. Zum Beispiel könnten Sie einen Bericht erstellen, der eine Übersicht über Abfragen über einen bestimmten Zeitraum gibt, wobei der Benutzer die Start- und Enddaten auswählt.
Benutzerdefinierte Berichte sind ein mächtiges Werkzeug, insbesondere wenn die vorgefertigten Berichte nicht alle Informationen liefern, die Sie benötigen, oder wenn Sie Daten in einem speziellen Format oder Layout präsentieren möchten.






Hinterlasse jetzt einen Kommentar