
Einführung in JSON
JSON (JavaScript Object Notation) ist ein leichtgewichtiges Datenformat, das auf der JavaScript-Syntax basiert und zum Austausch von Daten zwischen einem Server und einem Webclient verwendet wird. Es ist textbasiert, lesbar und einfach zu parsen und generieren.
Vorteile von JSON:
Einfachheit: Leicht zu lesen und zu schreiben für Menschen.
Kompatibilität: Weit verbreitet und unterstützt von vielen Programmiersprachen.
Die Flexibilität von JSON ermöglicht die Darstellung komplexer Datenstrukturen wie verschachtelter Objekte und Arrays. Allerdings weist das Datenformat auch Nachteile auf. Dazu zählt zunächst, dass Binärdaten nicht unterstützt werden. Aufgrund der textbasierten Struktur ist JSON nicht effizient für die Übertragung von Binärdaten. Zudem beansprucht JSON im Vergleich zu binären Formaten mehr Speicherplatz. Ein weiterer Nachteil ist, dass JSON-Daten kein Schema aufweisen. Dies kann zu Inkonsistenzen führen.
Die Version 2022 des Microsoft SQL Server verfügt über erweiterte Funktionen für die Arbeit mit JSON-Daten. Die genannten Erweiterungen erlauben die direkte Verarbeitung von JSON-Daten innerhalb der SQL-Server-Umgebung, ohne dass ein separates ETL-Tool (Extract, Transform, Load) erforderlich ist.
Die Vorteile der direkten Verarbeitung von JSON mit SQL Server lassen sich wie folgt zusammenfassen:
Die Effizienzsteigerung resultiert aus der Tatsache, dass kein Import der Daten vor der Verarbeitung erforderlich ist.
Des Weiteren ermöglicht die direkte Verarbeitung von JSON-Daten in SQL-Abfragen eine hohe Flexibilität.
Die nahtlose Integration in bestehende SQL-basierte Workflows und Anwendungen stellt einen weiteren Vorteil dar.
Besondere SQL-Anweisungen für JSON
SQL Server 2022 bietet eine Reihe von speziellen Funktionen und Anweisungen zur Arbeit mit JSON:
Zur Ausführung der genannten Beispiele steht die Datei zum Download bereit. Alternativ kann die Datei auch selbst erzeugt werden, indem der folgende Python-Code ausgeführt wird:
import json
import random
from datetime import datetime, timedelta
# Hilfsfunktionen
def generate_isbn():
return f"978{random.randint(1000000000, 9999999999)}"
def generate_price():
return round(random.uniform(4.99, 99.99), 2)
# Beispieldaten
categories = ["Fiction", "Non-Fiction", "Science Fiction", "Mystery", "Romance", "Biography", "History", "Science", "Self-Help", "Cooking"]
genres = ["Classic", "Contemporary", "Thriller", "Fantasy", "Young Adult", "Literary Fiction", "Historical Fiction", "Memoir", "Popular Science", "Business"]
languages = ["English", "German", "French", "Spanish", "Italian"]
authors = [
"J.K. Rowling", "Stephen King", "George R.R. Martin", "Jane Austen", "Ernest Hemingway",
"Agatha Christie", "Mark Twain", "Charles Dickens", "Virginia Woolf", "Leo Tolstoy",
# ... Fügen Sie hier mehr Autoren hinzu
]
# Hauptfunktion zur Datengenerierung
def generate_book_catalog(num_books=10000):
catalog = {"categories": []}
books_per_category = num_books // len(categories)
for cat_id, category in enumerate(categories, 1):
cat_data = {
"id": cat_id,
"name": category,
"description": f"Books in the {category} category",
"products": []
}
for book_id in range(1, books_per_category + 1):
book = {
"id": (cat_id - 1) * books_per_category + book_id,
"name": f"{category} Book {book_id}",
"author": random.choice(authors),
"description": f"A {random.choice(genres).lower()} book in the {category} category",
"price": generate_price(),
"publicationYear": random.randint(1900, 2023),
"isbn": generate_isbn(),
"pageCount": random.randint(100, 1000),
"genre": random.sample(genres, k=random.randint(1, 3)),
"language": random.choice(languages),
"stock": {
"warehouse1": random.randint(0, 500),
"warehouse2": random.randint(0, 500)
},
"ratings": {
"average": round(random.uniform(1, 5), 1),
"count": random.randint(0, 10000)
}
}
cat_data["products"].append(book)
catalog["categories"].append(cat_data)
return catalog
# Generiere den Katalog
book_catalog = generate_book_catalog()
# Speichere den Katalog als JSON-Datei
with open('product-catalog.json', 'w') as f:
json.dump(book_catalog, f, indent=2)
print("Buchkatalog mit 10.000 Datensätzen wurde erstellt und in 'product-catalog.json' gespeichert.")OPENJSON: Diese Funktion analysiert JSON-Text und gibt die JSON-Daten als Tabellenzeilen zurück.
-- Extrahieren der Hauptstruktur aus der JSON-Datei
DECLARE @json NVARCHAR(MAX);
-- Laden des JSON-Inhalts von der Datei in eine Variable
SELECT @json = BulkColumn
FROM OPENROWSET (BULK 'C:\TEMP\ODWH\product-catalog.json', SINGLE_CLOB) as j;
-- Analysieren der Struktur des JSON-Dokuments
SELECT [key], type, value
FROM OPENJSON(@json);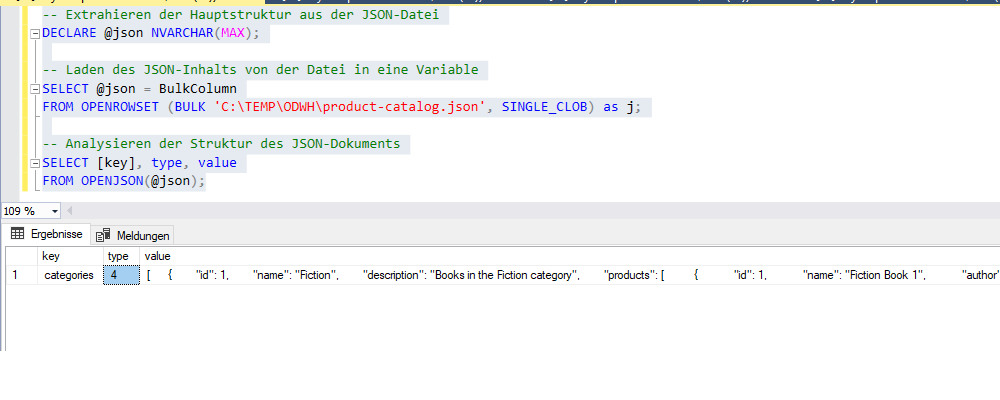
Der type-Wert von 4 zeigt normalerweise an, dass der JSON-Wert ein Array ist. Dies ist Teil der Rückgabe von OPENJSON, das den JSON-Inhalt analysiert und jeden Schlüssel-Wert-Paar-Typ angibt:
-
0: NULL1: string2: int3: bool4: array5: object
FOR JSON: Diese Klausel formatiert SQL-Abfrageergebnisse als JSON-Text.
SELECT [ProduktID]
,[ProduktName]
,[Beschreibung]
,[Preis]
,[MinMenge]
,[KategorieID]
FROM [DEV_ERP].[dbo].[Produkt]
FOR JSON PATH;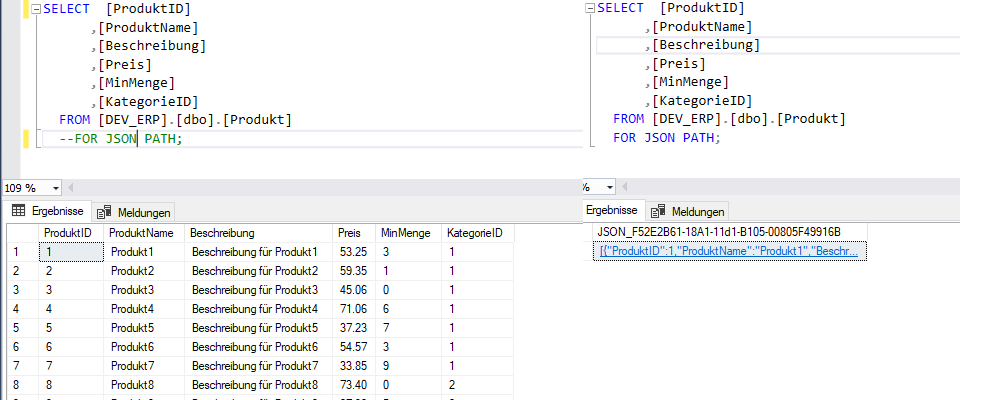
Hier gehen wir auf unsere Dev Produkt Tabelle, die wir hier erzeugen. Durch die Eingabe des Zusatzes „FOR JSON PATH” wird lediglich ein Datensatz zurückgegeben, der im JSON-Format vorliegt.
ISJSON: Diese Funktion überprüft, ob eine Zeichenfolge gültiges JSON ist.
-- Laden des JSON-Inhalts von der Datei in eine Variable
SELECT @json = BulkColumn
FROM OPENROWSET (BULK 'C:\TEMP\ODWH\product-catalog.json', SINGLE_CLOB) as j;
-- Überprüfen, ob der JSON-Inhalt gültig ist
SELECT ISJSON(@json) AS IsValidJson;In der Regel wird bei gültigem JSON eine Rückmeldung generiert: IsValidJson :1
JSON_VALUE: Extrahiert einen Wert aus einem JSON-Text.
-- Extrahieren der Hauptstruktur aus der JSON-Datei
DECLARE @json NVARCHAR(MAX);
-- Laden des JSON-Inhalts von der Datei in eine Variable
SELECT @json = BulkColumn
FROM OPENROWSET (BULK 'C:\TEMP\ODWH\product-catalog.json', SINGLE_CLOB) as j;
SELECT JSON_VALUE(@json, '$.categories[0].name') AS CategoryName;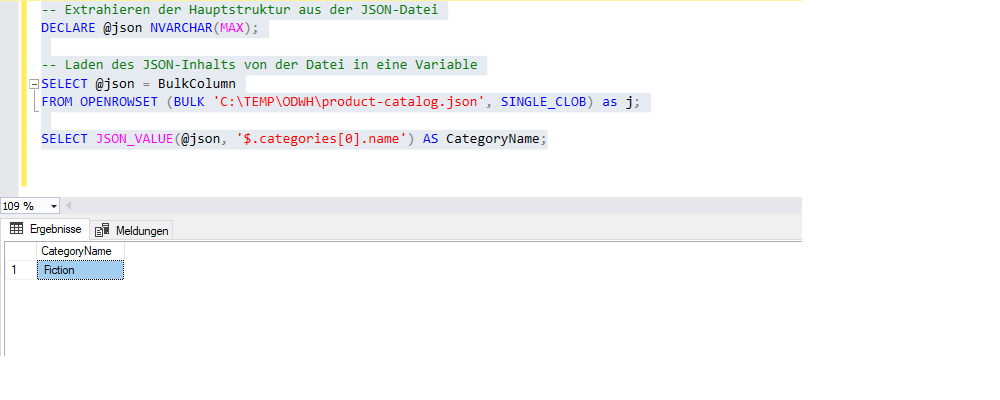
Die Verarbeitung von JSON in SQL Server ist insbesondere für kleine bis mittelgroße JSON-Dokumente effizient. Die Nutzung von Indizes auf JSON-Spalten kann die Abfrageleistung erheblich verbessern. Die Verarbeitung sehr großer oder stark verschachtelter JSON-Dokumente kann jedoch ressourcenintensiv sein.
Die Indexierung von JSON-Daten ist nur eingeschränkt möglich, was die Abfrageleistung beeinträchtigen kann. Die Schemaüberprüfung ist aufgrund der schemalosen Natur von JSON komplexer.
Die Integration von JSON in SQL Server 2022 bietet erhebliche Vorteile für die Arbeit mit JSON-Daten innerhalb der Datenbank. Sie ermöglicht eine effizientere und flexiblere Datenverarbeitung, was die Entwicklung und Verwaltung von Anwendungen vereinfacht. Dennoch sollten die potenziellen Einschränkungen hinsichtlich der Leistung sowie die Herausforderungen der Schemalosigkeit bei der Planung und Implementierung berücksichtigt werden.
Der vorliegende Beitrag behandelt die Extraktion und Analyse von JSON-Daten aus einer Datei unter Verwendung der SQL Server OPENROWSET-Funktion. Zur Veranschaulichung dient die JSON-Datei product-catalog.json, die sich unter C:\TEMP\ODWH\product-catalog.json befindet.
Im ersten Schritt wurde demonstriert, wie der Inhalt der JSON-Datei in eine SQL-Variable geladen und anschließend mit der OPENJSON-Funktion die Struktur und der Inhalt analysiert werden kann. Dabei wurde erlernt, dass der Type-Wert von 4 angibt, dass der JSON-Wert ein Array ist.
Um eine detaillierte Analyse durchzuführen, wurde die Hauptstruktur des JSON-Dokuments untersucht und anschließend die Struktur des Kategorien-Arrays weiter analysiert. Dies ermöglichte uns, die Typen und Werte der verschiedenen Elemente im JSON-Dokument zu verstehen.
Häufig gestellte Fragen (FAQ)







Hinterlasse jetzt einen Kommentar